
A noticia de que existem supersalários na Unicamp é antiga, mas voltou a circular recentemente, por conta da decisão do magnífico reitor de publicar a lista nominal – como exige o Tribunal de Contas do Estado. E já que chutaram o vespeiro, resolvi pegar o documento que a Diretoria Geral de Recursos Humanos publica e trabalhar um pouco os dados.
Tirando os dados do PDF e passando para o CSV
Começamos pelo documento, em PDF, péssimo pra trabalhar – mas no arsenal do Jornalista Hacker do Software Livre temos uma ferramenta ideal para isso: o Tabula. Instalar no Ubuntu é razoavelmente simples (pros outros sistemas, leia o README):
- Instale o Java, se não estiver instalado
- Baixe o programa do site oficial
- Descompacte e abra a pasta descompactada no terminal
- Execute a linha seguinte:
java -Dfile.encoding=utf-8 -Xms256M -Xmx1024M -jar tabula.jar
Seu navegador provavelmente vai abrir automaticamente na página do Tabula mas
se isso não acontecer, escreva http://127.0.0.1:8080 na barra de endereços e
aperte enter. A tela principal é meio óbvia, simplesmente clique em upload e
selecione seu arquivo. Nem encane com o Auto-Detect Tables, não é necessário
pra esse caso (e detecta errado neste PDF em particular).
Desenhe manualmente, na primeira página um retângulo que cubra toda a tabela.
Em seguida clique em Repeat this selection, para não precisar selecionar a
mesma área em todas as páginas – o Tabula faz isso por você. Finalmente,
clique em Download all data, o botão verde.
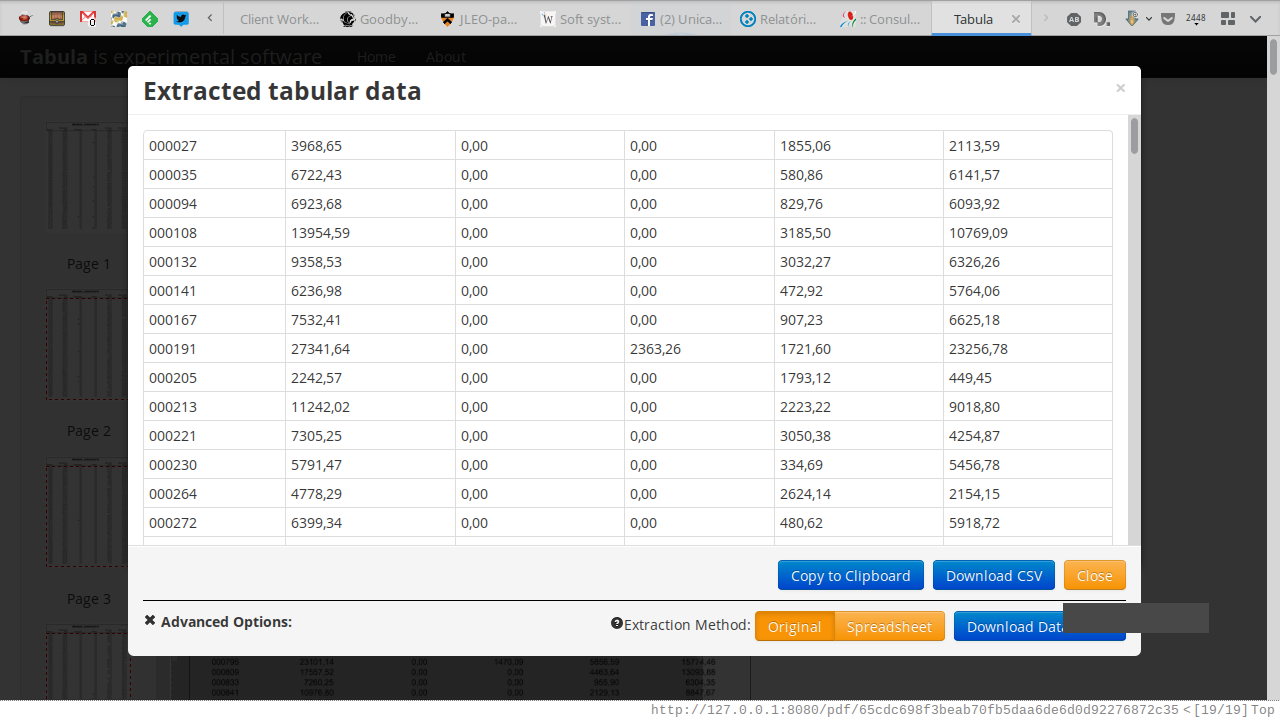
Vai demorar um pouco pra processar todas as páginas. No meu laptop, demorou 4 minutos. Mas eventualmente a tela atualizou e mostrou a opção de baixar todos os dados como CSV. Pronto, agora dá pra trabalhar direto com os dados.
Processando os dados com Python e CSVKit
A primeira coisa que eu tive que fazer com os dados em CSV foi trocar a virgula por ponto, pra ficar na notação decimal padrão do Python. Eu fiz isso com um script minúsculo em Python 3:
import csv
with open('./tabula-65cdc698f3beab70fb5daa6de6d0d92276872c35.csv') as inputdata,\
open('./remuneracao-decimais.csv', 'w') as outputdata:
datawriter = csv.writer(outputdata, dialect='unix')
for line in csv.reader(inputdata):
datawriter.writerow([cell.replace(',', '.') for cell in line])
Agora eu queria ordenar pelo salário bruto e pelo salário líquido, em cópias do arquivo. Eu poderia programar isso com Python puro, mas é tão melhor poder contar com uma solução pronta e empacotada pra gente! Por isso eu resolvi usar o CSVKit, um canivete suíço pra operar CSV na linha de comando.
Com o csvkit, ordenar foi simples, embora demorado. Cada comando abaixo levou uns 4 minutos – afinal, pra ordenar esse arquivo o programa precisa carregar as 140 mil linhas de dados e comparar. Mas como eu não precisei programar, eu fui tomar um suco.
csvsort -c 6 --reverse --no-header-row remuneracao-decimais.csv > remuneracao-por-liquido.csv
csvsort -c 1 --reverse --no-header-row remuneracao-decimais.csv > remuneracao-por-bruto.csv
Se você não tiver um suco para tomar, baixe o arquivo ordenado por salario bruto e o arquivo ordenado por salario liquido.
Pegando os nomes dos servidores
O PDF original não tinha os nomes, mas o número de matrícula dos servidores públicos. No entanto, a Unicamp tem um serviço que permite consultar funcionarios pela matricula. Portanto, foi só questão de escrever um robôzinho pra pegar esses dados usando meu framework favorito, o Scrapy.
Eu fiz um projetinho simples, que me permite automatizar a consulta pela matrícula do funcionário. O processo é meio dificultado porque o site nao me permite fazer muitas consultas em paralelo, então eu tive que limitar a apenas uma consulta a cada 7 segundos. O que dá mais ou menos 10 por minuto, no mínmo 10 minutos pra pegar 100 funcionarios ou quase 2 horas pra pegar os mil funcionarios com maior salário. Eu poderia rotear as consultas por outros servidores, pela rede Tor ou por um serviço especializado. Mas eu tenho tempo, posso ir fazer uma janta.
Pra rodar meu scraper, basta ter o Scrapy instalado, clonar o projeto e rodar:
scrapy crawl dgrh -o supersalarios.csv
Curiosamente, dos 100 primeiros resultados só 14 aparecem no site. O que significa que os outros 86 estão sendo protegidos ou simplesmente não existem. Se você quiser tentar com mais servidores, passe o parâmetro volume=666 para pegar 666 servidores:
scrapy crawl dgrh -a volume=666 supersalarios-top666.csv
Visualizando os dados
Duas curiosidades que me bateram: quantos servidores temos em cada faixa salarial (agrupada por salários mínimos). E qual o gasto total da Unicamp com cada faixa salarial?
Lidar com dados em Python é muito fácil. Pra começar, precisamos dar uma
limpada no CSV – pro CSV tudo é string, só uma sequência de letrinhas. Mas
nós sabemos que é um float, então vamos converter. E já aproveitamos para
deduzir onde agrupar: o valor dividido pelo salario minimo, sem o resto. No
Python, // é um operador para divisão sem resto. Então temos:
class Wage(object):
def __init__(self, data):
self.value = float(data.strip())
self.hist_bin = int(self.value // 788)
Agrupar valores costuma render algo parecido com um histograma. Eu resolvi
agrupar usando um defaultdict, que me permite usar a sintaxe de dicionário e
ter uma lista como valor padrão:
import csv
from collections import defaultdict
hist = defaultdict(list)
with open('./remuneracao-decimais.csv') as datafile:
reader = csv.reader(datafile)
for line in reader:
wage = Wage(line[1])
hist[wage.hist_bin].append(wage.value)
Finalmente, preparar os dados pra fazer os plots. Duas transformações em dicionários e basta escrever os CSV: gráfico dos gastos e gráfico da contagem de servidores.
plot_sum = {hist_bin: sum(paychecks) for hist_bin, paychecks in hist.items()}
plot_count = {hist_bin: len(paychecks) for hist_bin, paychecks in hist.items()}
with open('sumplot.csv', 'w') as plotfile:
writer = csv.writer(plotfile)
writer.writerows(plot_sum.items())
with open('countplot.csv', 'w') as plotfile:
writer = csv.writer(plotfile)
writer.writerows(plot_count.items())
Eu fiquei com preguiça de usar o Matplotlib, então eu resolvi usar o Plotly manualmente mesmo.
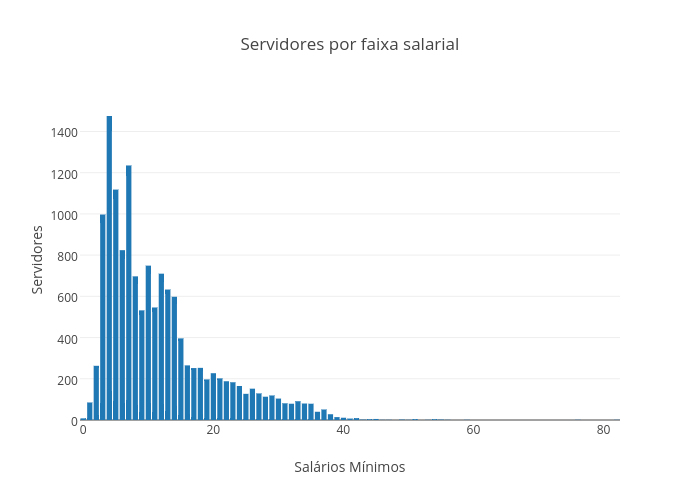
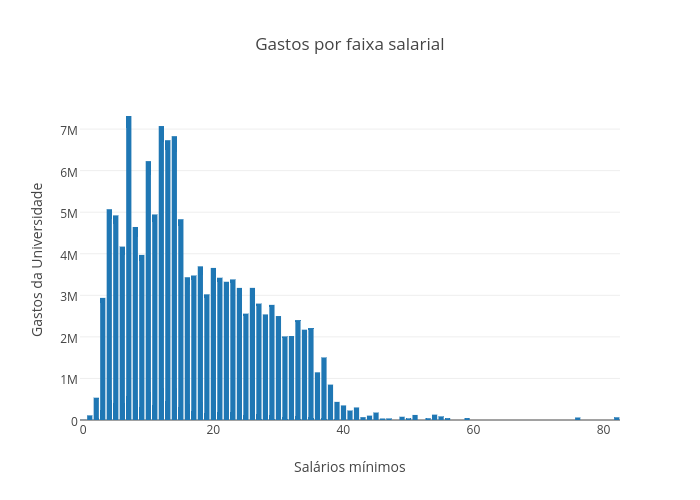
Fica a pergunta: porque temos tantas pessoas recebendo menos de um salário mínimo?